[문제 상황]
제가 근무하는 회사의 도메인은 이커머스입니다. 다른 이커머스 회사도 마찬가지겠지만, 연중 트래픽이 몰리는 시즌이 있습니다. 대표적으로 어버이날, 크리스마스, 명절이 있습니다.
이전까지만 해도 특정 시즌에 트래픽이 몰려도 데이터베이스에 큰 문제가 없었습니다. 그러나, 점차 서비스가 성장하면서 유저가 많아지게 되었습니다. 그러면서 작년 어버이날에 문제가 발생하게 되었습니다. 데이터베이스 연결에 문제가 생기고, 쿼리의 지연이 굉장히 길어지면서 타임 아웃이 발생하는 장애를 겪었습니다. 이를 해결하기 위해 급하게 읽기 전용 데이터베이스를 추가하고, 서버를 재부팅하면서 이를 해결하였습니다. 다만, 이전에 설정했던 읽기전용 데이터베이스에 쿼리 분산이 정상적으로 이뤄지지 않은 것을 확인했습니다. 이 문제에 대해서 한번 원인과 해결책을 살펴보도록 하겠습니다.
저희 회사는 AWS Aurora DB를 사용하며, 클러스터를 구성해서 쓰기/읽기 인스턴스를 구분하고 있었습니다.

api server는 스프링부트 어플리케이션입니다. HikariCP를 이용해서 데이터베이스와 커넥션을 연결하고 있습니다. 그리고 요청을 처리할 때 트랜젝션 readonly인 경우, 클러스터에서 제공하는 읽기전용 경로에 쿼리 요청을 보내도록 부하분산을 구현해두었습니다.
위 구조를 이용하면 slave3가 추가되면 RDS Cluster의 지원으로 기존에 있는 연결들이 조금 있다가 slave3에 라우팅 해주는 것으로 예상을 하고 있었습니다. 하지만 실제로 그렇지는 않았습니다. slave3가 추가되고 시간이 지나도 실제 커넥션이 연결되지 않았습니다. api를 재부팅하면서 그 때 slave3로 연결되는 것을 확인할 수 있었습니다.
문제의 원인은 AWS RDS Cluster 문서에서 찾아볼 수 있습니다.
Load balancing with the reader endpoint - Amazon Aurora MySQL Database Administrator’s Handbook
Load balancing with the reader endpoint Because the reader endpoint contains all Aurora Replicas, it can provide DNS-based, random reader assignment for new connections. Every time you resolve the reader endpoint, you'll get an instance IP that you can con
docs.aws.amazon.com
첫 문단부터 보면, 다음과 같이 설명되어있습니다.
Because the reader endpoint contains all Aurora Replicas, it can provide DNS-based, random reader assignment for new connections. Every time you resolve the reader endpoint, you'll get an instance IP that you can connect to, chosen randomly.
DNS works at the connection level (not the individual query level). You must keep resolving the endpoint without caching DNS to get a different instance IP on each resolution. If you only resolve the endpoint once and then keep the connection in your pool, every query on that connection goes to the same instance. If you cache DNS, you receive the same instance IP each time you resolve the endpoint.
읽기 엔드포인트는 모든 Aurora 복제본을 포함하기 때문에, 새로운 연결에 대해 DNS 기반의 무작위 리더 할당을 제공합니다. 읽기 엔드포인트를 해석할 때마다 무작위로 선택된 인스턴스 IP를 받게 됩니다.
DNS는 개별 쿼리 수준이 아닌 연결 수준에서 작동합니다. 다른 인스턴스 IP를 얻으려면 DNS를 캐시하지 않고 계속해서 엔드포인트를 해석해야 합니다. 엔드포인트를 한 번만 해석한 후에 그 연결을 풀에 유지하면, 해당 연결의 모든 쿼리는 동일한 인스턴스로 전송됩니다. DNS를 캐시하면 엔드포인트를 해석할 때마다 동일한 인스턴스 IP를 받게 됩니다.
즉, RDS Cluster에서 제공하는 읽기 전용 엔드포인트를 통해서 연결을 시도하면 클러스터는 읽기전용 인스턴스의 IP를 무작위로 받게 됩니다. 이 사실을 토대로 발생할 수 있는 현상을 나열해보자면,
- 하나의 풀에 있는 모든 커넥션이 하나의 인스턴스로 연결하게 됩니다.
- 무작위로 읽기전용 IP를 받기 때문에, 최악의 경우 모든 api들이 하나의 인스턴스에 연결하게 될 수도 있습니다.
- slave3를 추가해도 기존 커넥션이 slave1,2에 직접적으로 연결되기 때문에, 재부팅을 해야만 slave3로 갈 수 있습니다.
- 재부팅 하는건 크게 문제가 되지 않지만, 무작위이기 때문에 slave3에 연결되지 않을 수 있습니다.
추가적으로, DB Fail-Over 상황에서도 문제가 발생할 수 있습니다. api에서 write/read 전용 pool이 있는데 fail-over가 되면서 기존 slave1이 master로 승격됩니다. 그러면 api의 writer전용 pool은 새로운 master를 가리켜야합니다. 그러면, api서버도 전체 재부팅이 필요하게 되는 문제가 있습니다.
이러한 문제를 해결할 수 있는 것은 앞단에 커넥션을 관리하는 프록시를 설정하는 것 입니다. 역시 AWS는 RDS Proxy를 통해서 커넥션 프록시를 제공하고 있습니다.
[RDS Proxy]
RDS Proxy는 데이터베이스와 애플리케이션의 중간 계층으로 동작합니다.
- 무작위로 하나의 인스턴스 IP를 통해 연결하는 것과 다르게, RDS Proxy는 여러개의 slave로 연결해줍니다. 하나의 api 커넥션 풀에서 여러개의 slave instance로 연결할 수 있습니다.
- RDS Proxy가 있는 상황에서 fail-over는 아주 좋은 효과를 줍니다. api를 재부팅할 필요 없이 자체적으로 다른 경로로 라우팅해줍니다.
- 장애가 발생하게 되어 slave3를 추가하면, 자동으로 새로운 인스턴스로 연결해줍니다.
하지만, 단점도 있습니다. Blue-Green 배포는 RDS Proxy가 설정된 상황에서 할 수 없습니다.
RDS Proxy를 사용하지 않고, RDS Cluster에서 제공하는 경로를 이용하면 아래 그림과 같이 DB 인스턴스에 직접적으로 연결하게 됩니다.
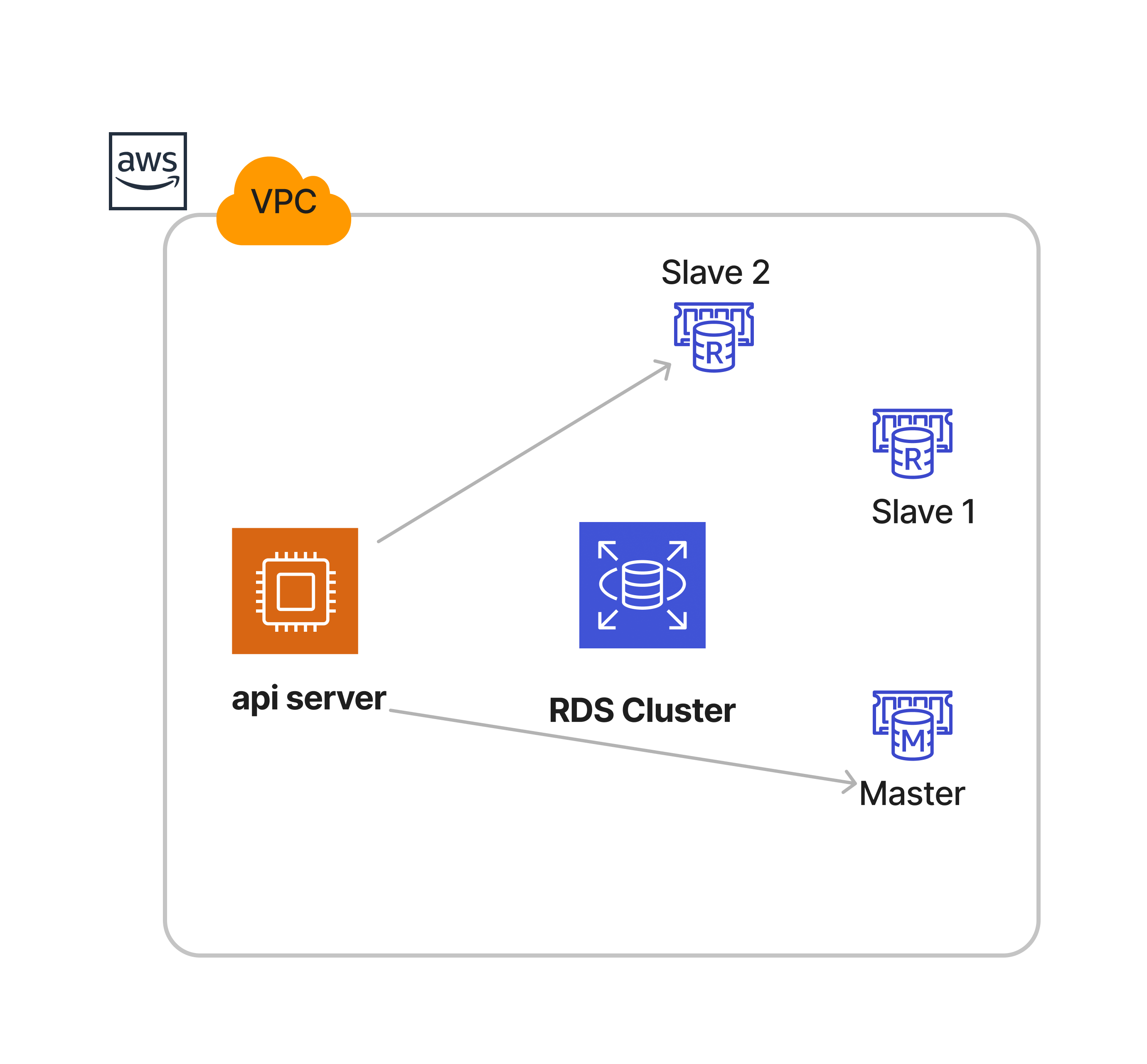
RDS Proxy를 앞단에 두고, 연결을 프록시가 관리하도록 변경하였습니다. 애플리케이션은 프록시에 연결을 요청하면 됩니다.

[문제 해결]
RDS Proxy를 통해서 위 구조로 변경을 하고 안정적으로 운영을 하면서, 어버이날 시즌이 또 맞이하게 되었습니다.이번 어버이날 시즌에는 데이터베이스 관련 이슈가 발생하지 않았습니다. 커넥션도 부하분산이 잘 되었습니다.fail-over에서 발생하는 문제도 프록시를 통해서 자동으로 처리해주는 것을 확인하였습니다.
RDS Cluster를 이용해서 데이터베이스에 연결하는 것보다, RDS Proxy를 통해서 구성하는게 더 효과적이라고 생각하게 된 계기였습니다. 추가적으로, AWS Lambda를 사용하게 된다면 위 구조를 꼭 이용하는걸 추천드립니다.
'Backend > AWS' 카테고리의 다른 글
| AWS Elastic Beanstalk에서 쿠버네티스로 전환하기 (0) | 2025.08.22 |
|---|---|
| AWS와 Elasticsearch를 이용해 실시간 검색 구현하기 (CDC) (0) | 2024.06.08 |

